 MENU
MENU 

A look back at 25 years of University of Michigan innovation in computer architecture

The University of Michigan has long held a reputation for leadership and innovation in computer architecture, with scholars and faculty across the Electrical Engineering and Computer Science (EECS) Department producing important, forward-thinking research that has advanced the field in significant ways. This record of cutting-edge contributions was recently recognized in a retrospective of the most significant and memorable papers of the last 25 years compiled by the International Symposium on Computer Architecture (ISCA).
In honor of its 50th anniversary, ISCA has released a volume of the most influential papers published from 1996 to 2020 with the aim of “tell[ing] a story of how research at ISCA progressed” over that 25-year period. Selected by a committee of ISCA program chairs from the last few years, the papers represented are credited with having made a meaningful and lasting mark on the field.
Nine papers by EECS researchers are among the 98 selected for inclusion in the retrospective, out of over a thousand total papers considered. The papers included are as follows, with the names of researchers formerly and/or currently affiliated with EECS in bold:
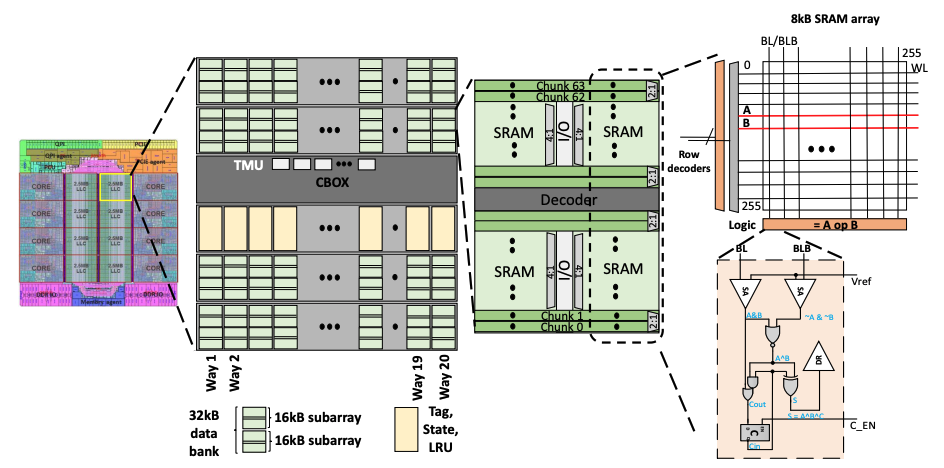
Neural cache: bit-serial in-cache acceleration of deep neural networks
Charles Eckert, Xiaowei Wang, Jingcheng Wang, Arun Subramaniyan, Ravi Iyer, Dennis Sylvester, David Blaauw, Reetuparna Das
Originally published in 2018 – Retrospective
Abstract: This paper presents the Neural Cache architecture, which re-purposes cache structures to transform them into massively parallel compute units capable of running inferences for Deep Neural Networks. Techniques to do in-situ arithmetic in SRAM arrays, create efficient data mapping and reducing data movement are proposed. The Neural Cache architecture is capable of fully executing convolutional, fully connected, and pooling layers in-cache. The proposed architecture also supports quantization in-cache. Our experimental results show that the proposed architecture can improve inference latency by 8.3× over state-of-art multi-core CPU (Xeon E5), 7.7× over server class GPU (Titan Xp), for Inception v3 model. Neural Cache improves inference throughput by 12.4× over CPU (2.2× over GPU), while reducing power consumption by 50% over CPU (53% over GPU).
Scalpel: Customizing DNN Pruning to the Underlying Hardware Parallelism
Jiecao Yu, Andrew Lukefahr, David Palframan, Ganesh Dasika, Reetuparna Das, Scott Mahlke
Originally published in 2017 – Retrospective
Abstract: As the size of Deep Neural Networks (DNNs) continues to grow to increase accuracy and solve more complex problems, their energy footprint also scales. Weight pruning reduces DNN model size and the computation by removing redundant weights. However, we implemented weight pruning for several popular networks on a variety of hardware platforms and observed surprising results. For many networks, the network sparsity caused by weight pruning will actually hurt the overall performance despite large reductions in the model size and required multiply-accumulate operations. Also, encoding the sparse format of pruned networks incurs additional storage space overhead. To overcome these challenges, we propose Scalpel that customizes DNN pruning to the underlying hardware by matching the pruned network structure to the data-parallel hardware organization. Scalpel consists of two techniques: SIMD-aware weight pruning and node pruning. For low-parallelism hardware (e.g., microcontroller), SIMD-aware weight pruning maintains weights in aligned fixed-size groups to fully utilize the SIMD units. For high-parallelism hardware (e.g., GPU), node pruning removes redundant nodes, not redundant weights, thereby reducing computation without sacrificing the dense matrix format. For hardware with moderate parallelism (e.g., desktop CPU), SIMD-aware weight pruning and node pruning are synergistically applied together. Across the microcontroller, CPU and GPU, Scalpel achieves mean speedups of 3.54x, 2.61x, and 1.25x while reducing the model sizes by 88%, 82%, and 53%. In comparison, traditional weight pruning achieves mean speedups of 1.90x, 1.06x, 0.41x across the three platforms.
Steven Pelley, Peter M. Chen, Thomas F. Wenisch
Originally published in 2014 – Retrospective
Abstract: Emerging nonvolatile memory technologies (NVRAM) promise the performance of DRAM with the persistence of disk. However, constraining NVRAM write order, necessary to ensure recovery correctness, limits NVRAM write concurrency and degrades throughput. We require new memory interfaces to minimally describe write constraints and allow high performance and high concurrency data structures. These goals strongly resemble memory consistency. Whereas memory consistency concerns the order that memory operations are observed between numerous processors, persistent memory systems must constrain the order that writes occur with respect to failure. We introduce memory persistency, a new approach to designing persistent memory interfaces, building on memory consistency. Similar to memory consistency, memory persistency models may be relaxed to improve performance. We describe the design space of memory persistency and desirable features that such a memory system requires. Finally, we introduce several memory persistency models and evaluate their ability to expose NVRAM write concurrency using two implementations of a persistent queue. Our results show that relaxed persistency models accelerate system throughput 30-fold by reducing NVRAM write constraints
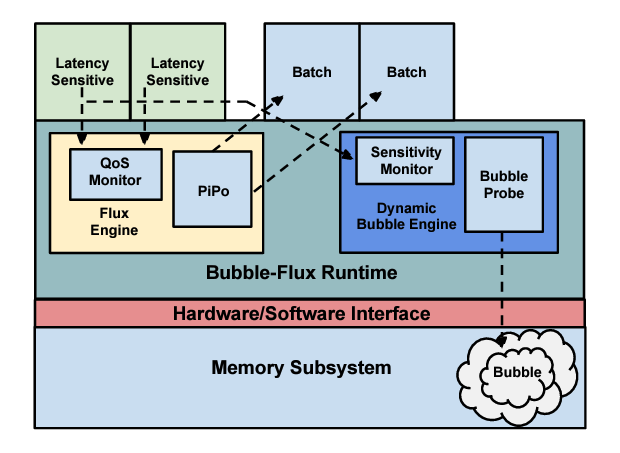
Bubble-flux: precise online QoS management for increased utilization in warehouse scale computers
Hailong Yang, Alex Breslow, Jason Mars, Lingjia Tang
Originally published in 2013 – Retrospective
Abstract: Ensuring the quality of service (QoS) for latency-sensitive applications while allowing co-locations of multiple applications on servers is critical for improving server utilization and reducing cost in modern warehouse-scale computers (WSCs). Recent work relies on static profiling to precisely predict the QoS degradation that results from performance interference among co-running applications to increase the number of “safe” co-locations. However, these static profiling techniques have several critical limitations: 1) a priori knowledge of all workloads is required for profiling, 2) it is difficult for the prediction to capture or adapt to phase or load changes of applications, and 3) the prediction technique is limited to only two co-running applications.
To address all of these limitations, we present Bubble-Flux, an integrated dynamic interference measurement and online QoS management mechanism to provide accurate QoS control and maximize server utilization. Bubble-Flux uses a Dynamic Bubble to probe servers in real time to measure the instantaneous pressure on the shared hardware resources and precisely predict how the QoS of a latency-sensitive job will be affected by potential co-runners. Once “safe” batch jobs are selected and mapped to a server, Bubble-Flux uses an Online Flux Engine to continuously monitor the QoS of the latency-sensitive application and control the execution of batch jobs to adapt to dynamic input, phase, and load changes to deliver satisfactory QoS. Batch applications remain in a state of flux throughout execution. Our results show that the utilization improvement achieved by Bubble-Flux is up to 2.2x better than the prior static approach.
Power management of online data-intensive services
David Meisner, Christopher M. Sadler, Luiz André Barroso, Wolf-Dietrich Weber, Thomas F. Wenisch
Originally published in 2011 – Retrospective
Abstract: Much of the success of the Internet services model can be attributed to the popularity of a class of workloads that we call Online Data-Intensive (OLDI) services. These workloads perform significant computing over massive data sets per user request but, unlike their offline counterparts (such as MapReduce computations), they require responsiveness in the sub-second time scale at high request rates. Large search products, online advertising, and machine translation are examples of workloads in this class. Although the load in OLDI services can vary widely during the day, their energy consumption sees little variance due to the lack of energy proportionality of the underlying machinery. The scale and latency sensitivity of OLDI workloads also make them a challenging target for power management techniques.
We investigate what, if anything, can be done to make OLDI systems more energy-proportional. Specifically, we evaluate the applicability of active and idle low-power modes to reduce the power consumed by the primary server components (processor, memory, and disk), while maintaining tight response time constraints, particularly on 95th-percentile latency. Using Web search as a representative example of this workload class, we first characterize a production Web search workload at cluster-wide scale. We provide a fine-grain characterization and expose the opportunity for power savings using low-power modes of each primary server component. Second, we develop and validate a performance model to evaluate the impact of processor- and memory-based low-power modes on the search latency distribution and consider the benefit of current and foreseeable low-power modes. Our results highlight the challenges of power management for this class of workloads. In contrast to other server workloads, for which idle low-power modes have shown great promise, for OLDI workloads we find that energy-proportionality with acceptable query latency can only be achieved using coordinated, full-system active low-power modes.
BugNet: Continuously Recording Program Execution for Deterministic Replay Debugging
Satish Narayanasamy, Gilles Pokam, Brad Calder
Originally published in 2005 – Retrospective
Abstract: Significant time is spent by companies trying to reproduce and fix the bugs that occur for released code. To assist developers, we propose the BugNet architecture to continuously record information on production runs. The information collected before the crash of a program can be used by the developers working in their execution environment to deterministically replay the last several million instructions executed before the crash. BugNet is based on the insight that recording the register file contents at any point in time, and then recording the load values that occur after that point can enable deterministic replaying of a program’s execution. BugNet focuses on being able to replay the application’s execution and the libraries it uses, but not the operating system. But our approach provides the ability to replay an application’s execution across context switches and interrupts. Hence, BugNet obviates the need for tracking program I/O, interrupts and DMA transfers, which would have otherwise required more complex hardware support. In addition, BugNet does not require a final core dump of the system state for replaying, which significantly reduces the amount of data that must be sent back to the developer.
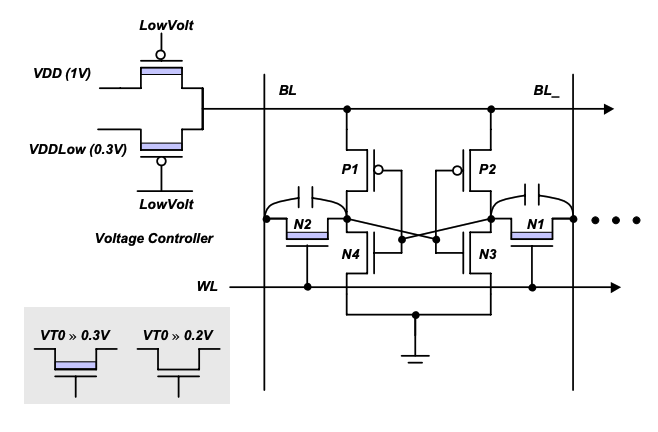
Drowsy Caches: Simple Techniques for Reducing Leakage Power
Krisztián Flautner, Nam Sung Kim, Steve Martin, David Blaauw, Trevor Mudge
Originally published in 2002 – Retrospective
Abstract: On-chip caches represent a sizable fraction of the total power consumption of microprocessors. Although large caches can significantly improve performance, they have the potential to increase power consumption. As feature sizes shrink, the dominant component of this power loss will be leakage. However, during a fixed period of time the activity in a cache is only centered on a small subset of the lines. This behavior can be exploited to cut the leakage power of large caches by putting the cold cache lines into a state preserving, low-power drowsy mode. Moving lines into and out of drowsy state incurs a slight performance loss. In this paper we investigate policies and circuit techniques for implementing drowsy caches. We show that with simple architectural techniques, about 80%-90% of the cache lines can be maintained in a drowsy state without affecting performance by more than 1%. According to our projections, in a 0.07um CMOS process, drowsy caches will be able to reduce the total energy (static and dynamic) consumed in the caches by 50%-75%. We also argue that the use of drowsy caches can simplify the design and control of low-leakage caches, and avoid the need to completely turn off selected cache lines and lose their state.
Detailed design and evaluation of redundant multithreading alternatives
Shubhendu Mukherjee, Michael Kontz, Steven K. Reinhardt
Originally published in 2002 – Retrospective
Abstract: Exponential growth in the number of on-chip transistors, coupled with reductions in voltage levels, makes each generation of microprocessors increasingly vulnerable to transient faults. In a multithreaded environment, we can detect these faults by running two copies of the same program as separate threads, feeding them identical inputs, and comparing their outputs, a technique we call Redundant Multithreading (RMT).This paper studies RMT techniques in the context of both single- and dual-processor simultaneous multithreaded (SMT) single-chip devices. Using a detailed, commercial-grade, SMT processor design we uncover subtle RMT implementation complexities, and find that RMT can be a more significant burden for single-processor devices than prior studies indicate. However, a novel application of RMT techniques in a dual-processor device, which we term chip-level redundant threading (CRT), shows higher performance than lockstepping the two cores, especially on multithreaded workloads.
A performance comparison of contemporary DRAM architectures
Vinodh Cuppu, Bruce Jacob, Brian Davis, Trevor Mudge
Originally published in 1999
Abstract: In response to the growing gap between memory access time and processor speed, DRAM manufacturers have created several new DRAM architectures. This paper presents a simulation-based performance study of a representative group, each evaluated in a small system organization. These small-system organizations correspond to workstation-class computers and use on the order of 10 DRAM chips. The study covers Fast Page Mode, Extended Data Out, Synchronous, Enhanced Synchronous, Synchronous Link, Rambus, and Direct Rambus designs. Our simulations reveal several things: (a) current advanced DRAM technologies are attacking the memory bandwidth problem but not the latency problem; (b) bus transmission speed will soon become a primary factor limiting memory-system performance; (c) the post-L2 address stream still contains significant locality, though it varies from application to application; and (d) as we move to wider buses, row access time becomes more prominent, making it important to investigate techniques to exploit the available locality to decrease access time.