 MENU
MENU 

Fourteen papers by ECE researchers to be presented at the International Conference on Machine Learning
ECE researchers will be presenting fourteen papers at the Forty-first International Conference on Machine Learning (ICML), the leading international academic conference in machine learning, held in Vienna, Austria, Jul 21-27.
The problems tackled by ECE faculty and students include transformer & large language models, diffusion generative models, multi-label classification models, nonconvex optimization, and more.
The following papers are being presented at the conference, with the names of ECE researchers in bold. The first paper, Compressible Dynamics in Deep Overparamaterized Low-Rank Learning & Adaptation, was selected for oral presentation.
Compressible Dynamics in Deep Overparameterized Low-Rank Learning & Adaptation
Can Yaras, Peng Wang, Laura Balzano, Qing Qu
Selected for oral presentation (1.58% acceptance rate)

Abstract: While overparameterization in machine learning models offers great benefits in terms of optimization and generalization, it also leads to increased computational requirements as model sizes grow. In this work, we show that by leveraging the inherent low-dimensional structures of data and compressible dynamics within the model parameters, we can reap the benefits of overparameterization without the computational burdens. In practice, we demonstrate the effectiveness of this approach for deep low-rank matrix completion as well as fine-tuning language models. Our approach is grounded in theoretical findings for deep overparameterized low-rank matrix recovery, where we show that the learning dynamics of each weight matrix are confined to an invariant low-dimensional subspace. Consequently, we can construct and train compact, highly compressed factorizations possessing the same benefits as their overparameterized counterparts. In the context of deep matrix completion, our technique substantially improves training efficiency while retaining the advantages of overparameterization. For language model fine-tuning, we propose a method called “Deep LoRA”, which improves the existing low-rank adaptation (LoRA) technique, leading to reduced overfitting and a simplified hyperparameter setup, while maintaining comparable efficiency. We validate the effectiveness of Deep LoRA on natural language tasks, particularly when fine-tuning with limited data. Our code is available at https://github.com/cjyaras/deep-lora-transformers.
Read the paper: Compressible Dynamics in Deep Overparameterized Low-Rank Learning & Adaptation.
A Global Geometric Analysis of Maximal Coding Rate Reduction
Peng Wang, Huikang Liu, Druv Pai, Yaodong Yu, Zhihui Zhu, Qing Qu, Yi Ma

Abstract: The maximal coding rate reduction (MCR2) objective for learning structured and compact deep representations is drawing increasing attention, especially after its recent usage in the derivation of fully explainable and highly effective deep network architectures. However, it lacks a complete theoretical justification: only the properties of its global optima are known, and its global landscape has not been studied. In this work, we give a complete characterization of the properties of all its local and global optima, as well as other types of critical points. Specifically, we show that each (local or global) maximizer of the MCR2 problem corresponds to a low-dimensional, discriminative, and diverse representation, and furthermore, each critical point of the objective is either a local maximizer or a strict saddle point. Such a favorable landscape makes MCR2 a natural choice of objective for learning diverse and discriminative representations via first-order optimization methods. To validate our theoretical findings, we conduct extensive experiments on both synthetic and real data sets.
Read the paper: A Global Geometric Analysis of Maximal Coding Rate Reduction.
Optimal Eye Surgeon: Finding image priors through sparse generators at initialization
Avrajit Ghosh, Xitong Zhang, Kenneth Sun, Qing Qu, Saiprasad Ravishankar, Rongrong Wang

Abstract: We introduce Optimal Eye Surgeon (OES), a framework for pruning and training deep image generator networks. Typically, untrained deep convolutional networks, which include image sampling operations, serve as effective image priors (Ulyanov et al., 2018). However, they tend to overfit to noise in image restoration tasks due to being overparameterized. OES addresses this by adaptively pruning networks at random initialization to a level of underparameterization. This process effectively captures low-frequency image components even without training, by just masking. When trained to fit noisy image, these pruned subnetworks, which we term Sparse-DIP, resist overfitting to noise. This benefit arises from underparameterization and the regularization effect of masking, constraining them in the manifold of image priors (Figure-3). We demonstrate that subnetworks pruned through OES surpass other leading pruning methods, such as the Lottery Ticket Hypothesis, which is known to be suboptimal for image recovery tasks (Wu et al., 2023). Our extensive experiments demonstrate the transferability of OES-masks and the characteristics of sparse-subnetworks for image generation. Code is available at https://github.com/Avra98/Optimal-Eye-Surgeon.git.
Generalized Neural Collapse for a Large Number of Classes
Jiachen Jiang, Jinxin Zhou, Peng Wang, Qing Qu, Dustin Mixon, Chong You, Zhihui Zhu

Abstract: Neural collapse provides an elegant mathematical characterization of learned last layer representations (a.k.a. features) and classifier weights in deep classification models. Such results not only provide insights but also motivate new techniques for improving practical deep models. However, most of the existing empirical and theoretical studies in neural collapse focus on the case that the number of classes is small relative to the dimension of the feature space. This paper extends neural collapse to cases where the number of classes are much larger than the dimension of feature space, which broadly occur for language models, retrieval systems, and face recognition applications. We show that the features and classifier exhibit a generalized neural collapse phenomenon, where the minimum one-vs-rest margins is maximized. We provide empirical study to verify the occurrence of generalized neural collapse in practical deep neural networks. Moreover, we provide theoretical study to show that the generalized neural collapse provably occurs under unconstrained feature model with spherical constraint, under certain technical conditions on feature dimension and number of classes.
Read the paper: Generalized Neural Collapse for a Large Number of Classes.
Neural Collapse in Multi-label Learning with Pick-all-label Loss
Pengyu Li, Yutong Wang, Xiao Li, Qing Qu
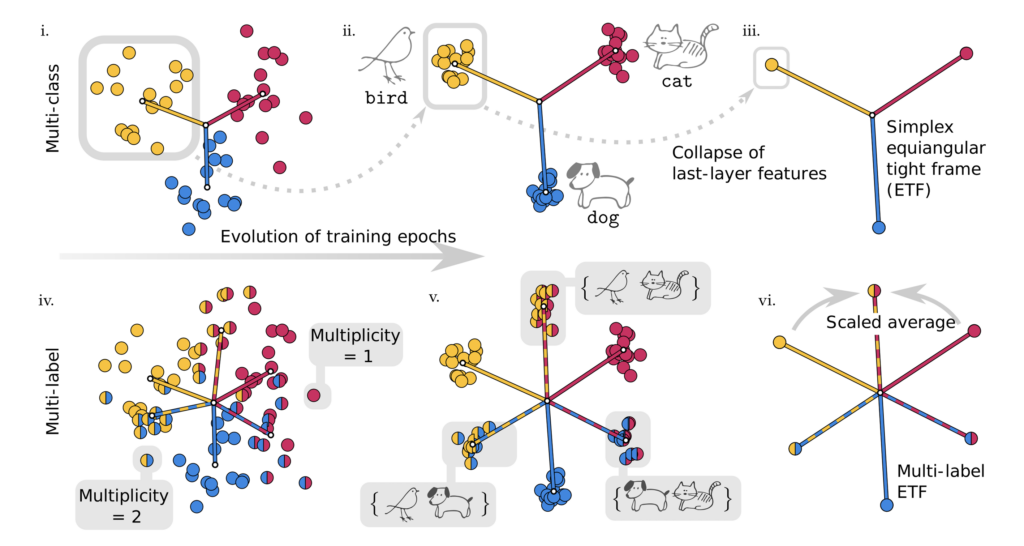
Abstract: We study deep neural networks for the multi-label classification (MLab) task through the lens of neural collapse (NC). Previous works have been restricted to the multi-class classification setting and discovered a prevalent NC phenomenon comprising of the following properties for the last-layer features: (i) the variability of features within every class collapses to zero, (ii) the set of feature means form an equi-angular tight frame (ETF), and (iii) the last layer classifiers collapse to the feature mean upon some scaling. We generalize the study to multi-label learning, and prove for the first time that a generalized NC phenomenon holds with the “pick-all-label” formulation, which we term as MLab NC. While the ETF geometry remains consistent for features with a single label, multi-label scenarios introduce a unique combinatorial aspect we term the “tag-wise average” property, where the means of features with multiple labels are the scaled averages of means for single-label instances. Theoretically, under proper assumptions on the features, we establish that the only global optimizer of the pick-all-label cross-entropy loss satisfy the multi-label NC. In practice, we demonstrate that our findings can lead to better test performance with more efficient training techniques for MLab learning.
Read the paper: Neural Collapse in Multi-label Learning with Pick-all-label Loss.
Matrix Completion with ReLU Sampling
Huikang Liu, Peng Wang, Longxiu Huang, Qing Qu, Laura Balzano

Abstract: We study the problem of symmetric positive semi-definite low-rank matrix completion (MC) with deterministic entry-dependent sampling. In particular, we consider rectified linear unit (ReLU) sampling, where only positive entries are observed, as well as a generalization to threshold-based sampling. We first empirically demonstrate that the landscape of this MC problem is not globally benign: Gradient descent (GD) with random initialization will generally converge to stationary points that are not globally optimal. Nevertheless, we prove that when the matrix factor with a small rank satisfies mild assumptions, the nonconvex objective function is geodesically strongly convex on the quotient manifold in a neighborhood of a planted low-rank matrix. Moreover, we show that our assumptions are satisfied by a matrix factor with i.i.d. Gaussian entries. Finally, we develop a tailor-designed initialization for GD to solve our studied formulation, which empirically always achieves convergence to the global minima. We also conduct extensive experiments and compare MC methods, investigating convergence and completion performance with respect to initialization, noise level, dimension, and rank.
Read the paper: Matrix Completion with ReLU Sampling.
The Emergence of Reproducibility and Consistency in Diffusion Models
Huijie Zhang, Jinfan Zhou, Yifu Lu, Minzhe Guo, Peng Wang, Liyue Shen, Qing Qu

Abstract: In this work, we investigate an intriguing and prevalent phenomenon of diffusion models which we term as “consistent model reproducibility”: given the same starting noise input and a deterministic sampler, different diffusion models often yield remarkably similar outputs. We confirm this phenomenon through comprehensive experiments, implying that different diffusion models consistently reach the same data distribution and scoring function regardless of diffusion model frameworks, model architectures, or training procedures. More strikingly, our further investigation implies that diffusion models are learning distinct distributions affected by the training data size. This is supported by the fact that the model reproducibility manifests in two distinct training regimes: (i) “memorization regime”, where the diffusion model overfits to the training data distribution, and (ii) “generalization regime”, where the model learns the underlying data distribution. Our study also finds that this valuable property generalizes to many variants of diffusion models, including those for conditional use, solving inverse problems, and model fine-tuning. Finally, our work raises numerous intriguing theoretical questions for future investigation and highlights practical implications regarding training efficiency, model privacy, and the controlled generation of diffusion models.
Read the paper: The Emergence of Reproducibility and Consistency in Diffusion Models.
Convergence and Complexity Guarantee for Inexact First-order Riemannian Optimization Algorithms
Yuchen Li, Laura Balzano, Deanna Needell, Hanbaek Lyu

Abstract: We analyze inexact Riemannian gradient descent (RGD) where Riemannian gradients and retractions are inexactly (and cheaply) computed. Our focus is on understanding when inexact RGD converges and what is the complexity in the general nonconvex and constrained setting. We answer these questions in a general framework of tangential Block Majorization-Minimization (tBMM). We establish that tBMM converges to an ϵ-stationary point within O(ϵ−2) iterations. Under a mild assumption, the results still hold when the subproblem is solved inexactly in each iteration provided the total optimality gap is bounded. Our general analysis applies to a wide range of classical algorithms with Riemannian constraints including inexact RGD and proximal gradient method on Stiefel manifolds. We numerically validate that tBMM shows improved performance over existing methods when applied to various problems, including nonnegative tensor decomposition with Riemannian constraints, regularized nonnegative matrix factorization, and low-rank matrix recovery problems.
Compositional Capabilities of Autoregressive Transformers: A Study on Synthetic, Interpretable Tasks
Rahul Ramesh, Ekdeep Singh Lubana, Mikail Khona, Robert Dick, Hidenori Tanaka

Abstract: Transformers trained on huge text corpora exhibit a remarkable set of capabilities, e.g., performing basic arithmetic. Given the inherent compositional nature of language, one can expect the model to learn to compose these capabilities, potentially yielding a combinatorial explosion of what operations it can perform on an input. Motivated by the above, we train autoregressive Transformer models on a synthetic data-generating process that involves compositions of a set of well-defined monolithic capabilities. Through a series of extensive and systematic experiments on this data-generating process, we show that: (1) autoregressive Transformers can learn compositional structures from small amounts of training data and generalize to exponentially or even combinatorially many functions; (2) generating intermediate outputs when composing functions is more effective for generalizing to new, unseen compositions than not generating any intermediate outputs (3) biases in the order of the compositions in the training data result in Transformers that fail to compose some combinations of functions; and (4) the attention layers select which capability to apply while the feed-forward layers execute the selected capability.
Towards an Understanding of Stepwise Inference in Transformers: A Synthetic Graph Navigation Model
Mikail Khona, Maya Okawa, Jan Hula, Rahul Ramesh, Kento Nishi, Robert Dick, Ekdeep Singh Lubana, Hidenori Tanaka

Abstract: Stepwise inference protocols, such as scratchpads and chain-of-thought, help language models solve complex problems by decomposing them into a sequence of simpler subproblems. Despite the significant gain in performance achieved via these protocols, the underlying mechanisms of stepwise inference have remained elusive. To address this, we propose to study autoregressive Transformer models on a synthetic task that embodies the multi-step nature of problems where stepwise inference is generally most useful. Specifically, we define a graph navigation problem wherein a model is tasked with traversing a path from a start to a goal node on the graph. Despite is simplicity, we find we can empirically reproduce and analyze several phenomena observed at scale: (i) the stepwise inference reasoning gap, the cause of which we find in the structure of the training data; (ii) a diversity-accuracy tradeoff in model generations as sampling temperature varies; (iii) a simplicity bias in the model’s output; and (iv) compositional generalization and a primacy bias with in-context exemplars. Overall, our work introduces a grounded, synthetic framework for studying stepwise inference and offers mechanistic hypotheses that can lay the foundation for a deeper understanding of this phenomenon.
Can Mamba Learn How To Learn? A Comparative Study on In-Context Learning Tasks
Jong Ho Park, Jaden Park, Zheyang Xiong, Nayoung Lee, Jaewoong Cho, Samet Oymak, Kangwook Lee, Dimitris Papailiopoulos

Abstract: State-space models (SSMs), such as Mamba (Gu & Dao, 2023), have been proposed as alternatives to Transformer networks in language modeling, by incorporating gating, convolutions, and input-dependent token selection to mitigate the quadratic cost of multi-head attention. Although SSMs exhibit competitive performance, their in-context learning (ICL) capabilities, a remarkable emergent property of modern language models that enables task execution without parameter optimization, remain underexplored compared to Transformers. In this study, we evaluate the ICL performance of SSMs, focusing on Mamba, against Transformer models across various tasks. Our results show that SSMs perform comparably to Transformers in standard regression ICL tasks, while outperforming them in tasks like sparse parity learning. However, SSMs fall short in tasks involving non-standard retrieval functionality. To address these limitations, we introduce a hybrid model, MambaFormer, that combines Mamba with attention blocks, surpassing individual models in tasks where they struggle independently. Our findings suggest that hybrid architectures offer promising avenues for enhancing ICL in language models.
Read the paper: Can Mamba Learn How To Learn? A Comparative Study on In-Context Learning Tasks.
Understanding Self-Attention through Prompt-Conditioned Markov Chains
Muhammed Ildiz, Yixiao Huang, Yingcong Li, Ankit Singh Rawat, Samet Oymak

Abstract: Modern language models rely on the transformer architecture and attention mechanism to perform language understanding and text generation. In this work, we study learning a 1-layer self-attention model from a set of prompts and associated output data sampled from the model. We first establish a precise mapping between the self-attention mechanism and Markov models: Inputting a prompt to the model samples the output token according to a context-conditioned Markov chain (CCMC) which weights the transition matrix of a base Markov chain. Additionally, incorporating positional encoding results in position-dependent scaling of the transition probabilities. Building on this formalism, we develop identifiability/coverage conditions for the prompt distribution that guarantee consistent estimation and establish sample complexity guarantees under IID samples. Finally, we study the problem of learning from a single output trajectory generated from an initial prompt. We characterize an intriguing winner-takes-all phenomenon where the generative process implemented by self-attention collapses into sampling a limited subset of tokens due to its non-mixing nature. This provides a mathematical explanation to the tendency of modern LLMs to generate repetitive text. In summary, the equivalence to CCMC provides a simple but powerful framework to study self-attention and its properties.
Read the paper: Understanding Self-Attention through Prompt-Conditioned Markov Chains.
Testing the Feasibility of Linear Programs with Bandit Feedback
Aditya Gangrade, Aditya Gopalan, Venkatesh Saligrama, Clay Scott

Abstract: While the recent literature has seen a surge in the study of constrained bandit problems, all existing methods for these begin by assuming the feasibility of the underlying problem. We initiate the study of testing such feasibility assumptions, and in particular address the problem in the linear bandit setting, thus characterising the costs of feasibility testing for an unknown linear program using bandit feedback. Concretely, we test if ∃x:Ax≥0 for an unknown A∈ℝm×d, by playing a sequence of actions xt∈ℝd, and observing Axt+noise in response. By identifying the hypothesis as determining the sign of the value of a minimax game, we construct a novel test based on low-regret algorithms and a nonasymptotic law of iterated logarithms. We prove that this test is reliable, and adapts to the `signal level,’ Γ, of any instance, with mean sample costs scaling as Õ(d2/Γ2). We complement this by a minimax lower bound of Ω(d/Γ2) for sample costs of reliable tests, dominating prior asymptotic lower bounds by capturing the dependence on d, and thus elucidating a basic insight missing in the extant literature on such problems.
Read the paper: Testing the Feasibility of Linear Programs with Bandit Feedback.
Graph Mixup on Approximate Gromov–Wasserstein Geodesics
Zhichen Zeng, Ruizhong Qiu, Zhe Xu, Zhining Liu, Yuchen Yan, Tianxin Wei, Lei Ying, Jingrui He, Hanghang Tong

Abstract: Mixup, which generates synthetic training samples on the data manifold, has been shown to be highly effective in augmenting Euclidean data. However, finding a proper data manifold for graph data is non-trivial, as graphs are non-Euclidean data in disparate spaces. Though efforts have been made, most of the existing graph mixup methods neglect the intrinsic geodesic guarantee, thereby generating inconsistent sample-label pairs. To address this issue, we propose GeoMix to mixup graphs on the Gromov-Wasserstein (GW) geodesics. A joint space over input graphs is first defined based on the GW distance, and graphs are then transformed into the GW space through equivalence-preserving transformations. We further show that the linear interpolation of the transformed graph pairs defines a geodesic connecting the original pairs on the GW manifold, hence ensuring the consistency between generated samples and labels. An accelerated mixup algorithm on the approximate low-dimensional GW manifold is further proposed. Extensive experiments show that the proposed GeoMix promotes the generalization and robustness of GNN models.
Read the paper: Graph Mixup on Approximate Gromov–Wasserstein Geodesics.