 MENU
MENU 

CSE researchers present 9 papers at leading AI conference
Researchers at U-M CSE have been accepted to present nine papers at the 2020 Association for the Advancement of AI (AAAI) Conference, one of the top conferences in the field of artificial intelligence. The students and faculty submitted projects spanning several key application areas for AI, including healthcare, finance, games, and robotics.
Learn more about the papers:
 Enlarge
EnlargeBounding Regret in Empirical Games
Steven Jecmen (Carnegie Mellon University); Arunesh Sinha (Singapore Management University); Zun Li (University of Michigan); Long TranThanh (University of Southampton)
Real-world multi-agent interactions are often immensely complex, unstructured, and bring about randomness and unknown utilities. These real-world problems aren’t amenable to theoretical analysis because of their complexity, which led to the development of the area of empirical (or simulated) games. This method of analysis has been used successfully to model and solve complex multi-agent game interactions in stock markets and cyber-security problems. In this paper, the authors tackle a problem with empirical games’ output solution, which typically lack a guarantee about the quality of the output. They approach this by calculating the regret in a game, and demonstrate the effectiveness of their approach with an extensive set of comparative experiments.
 Enlarge
EnlargeGenerating Realistic Stock Market Order Streams
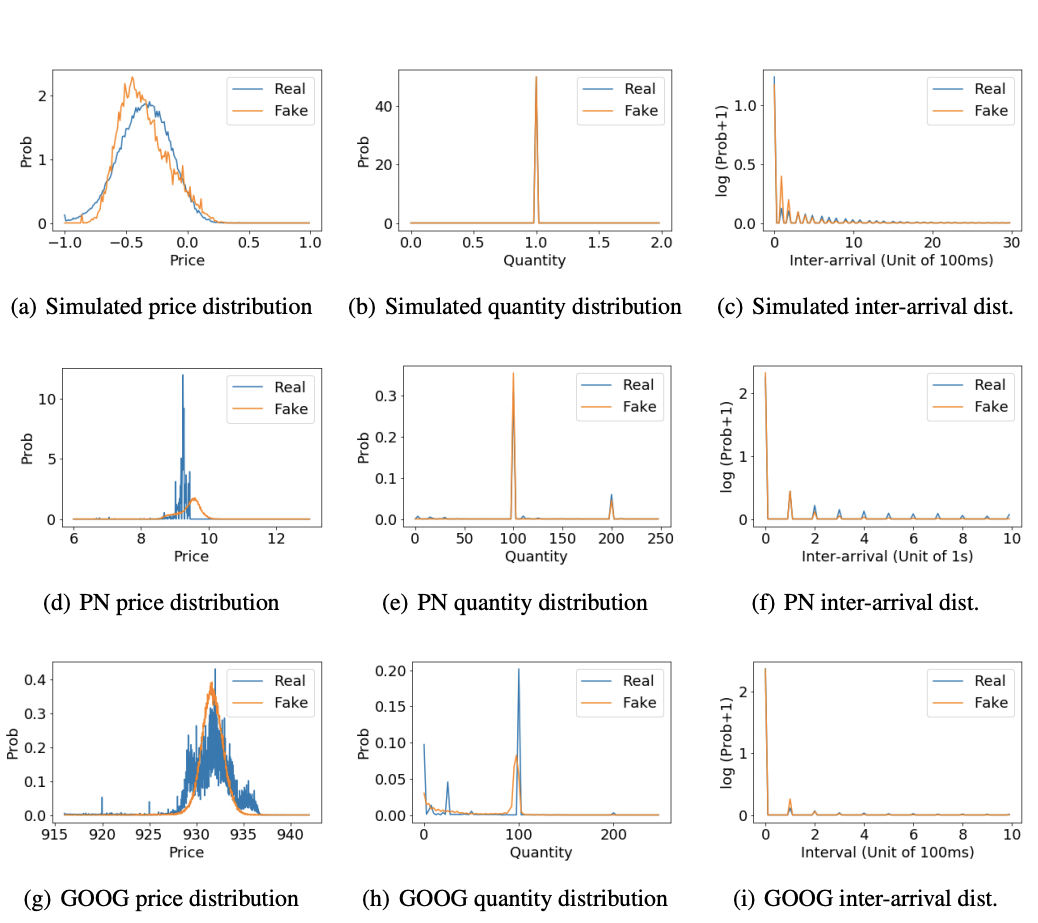
Junyi Li (University of Michigan); Xintong Wang (University of Michigan); Yaoyang Lin (University of Michigan); Arunesh Sinha (Singapore Management University)*; Michael Wellman (University of Michigan)
Modeling broad trends in financial markets has led to a number of automated methods to identify issues in real time, like market manipulation. To build these models, analysts require huge amounts of financial data with the proper labels needed to train machine learning algorithms. Unfortunately, the vast sums of actual trades and stock orders generated every day lack critical labels that identify when things like market manipulation have occured. To meet this need, the authors have used adversarial machine learning techniques to generate artificial but realistic stock market order streams.
 Enlarge
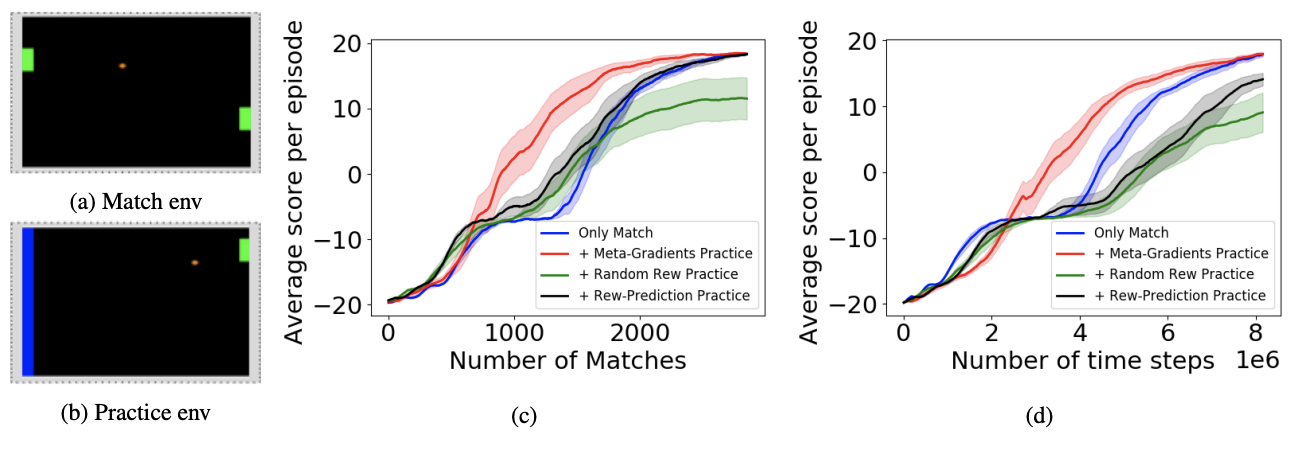
EnlargeJanarthanan Rajendran (University of Michigan); Richard Lewis (University of Michigan); Vivek Veeriah (University of Michigan); Honglak Lee (University of Michigan); Satinder Singh (University of Michigan)
The authors present a method for an autonomous agent to learn intrinsic reward functions that drive that agent to continue learning even during practice sessions that don’t present an external reward. They propose a setup of alternating periods of practice and evaluation, where the agent’s environment may differ but it must use the practice as a means to better perform during the evaluation (called a match). They evaluated their method in two games in which the practice environment differs from match: Pong, with practice against a wall without an opponent, and PacMan, with practice in a maze without ghosts. The results showed gains from learning in practice and match periods over learning in just matches.
 Enlarge
EnlargeAditya Modi (University of Michigan); Debadeepta Dey (Microsoft); Alekh Agarwal (Microsoft); Adith Swaminathan (Microsoft Research); Besmira Nushi (Microsoft Research); Sean Andrist (Microsoft Research); Eric Horvitz (MSR)
Assemblies of modular subsystems are being used to perform sensing, reasoning, and decision making in high-stakes, time-critical tasks in such areas as transportation, healthcare, and industrial automation. The authors address the opportunity to maximize the utility of an overall computing system by using reinforcement learning to guide the configuration of the set of interacting modules that comprise the system. They designed metareasoning techniques that consider a rich representation of the input, monitor the state of the entire pipeline, and adjust the configuration of modules on-the-fly so as to maximize the utility of a system’s operation.
 Enlarge
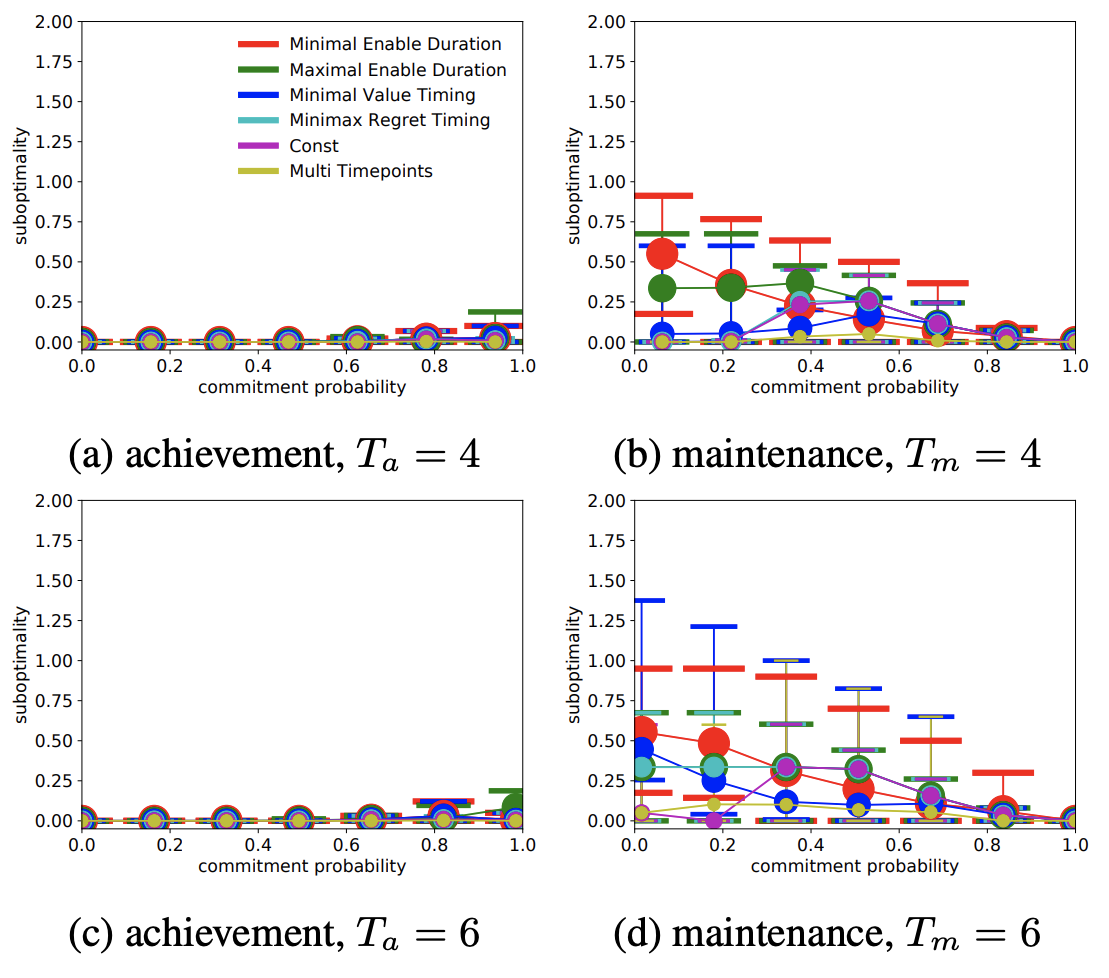
EnlargeModeling Probabilistic Commitments for Maintenance Is Inherently Harder than for Achievement
Qi Zhang (University of Michigan); Edmund Durfee (University of Michigan); Satinder Singh (University of Michigan)
In systems of multiple autonomous agents, the individual agents are often interdependent in that what one agent does can help or hinder another. This paper considers a form of commitment relationships between agents, called a maintenance commitment, where the provider of a condition commits to courses of action that, up until a promised time, are sufficiently unlikely to change features set the way the recipient wants them maintained. This differs from achievement commitments, which describe requests to change conditions a certain way. This paper argues that a maintenance commitment is fundamentally harder for the recipient to model safely than an achievement commitment.
 Enlarge
EnlargePrivacy Enhanced Multimodal Neural Representations for Emotion Recognition
Mimansa Jaiswal (University of Michigan); Emily Mower Provost (University of Michigan)
This paper demonstrates that machine learning algorithms working on tasks like emotional recognition store a significant amount of demographic and identifying data about the audio data being analyzed. To counter this, the authors demonstrate that rather than storing the raw data, storing representations of the data that remove this identifying information doesn’t negatively impact performance on the primary emotion recognition task. They used adversarial learning to unlearn the private information present in a representation, and investigated the effect of varying the strength of the adversarial component on the primary task and on the ability of an attacker to predict specific demographic information.
 Enlarge
EnlargeQuerying to Find a Safe Policy Under Uncertain Safety Constraints in Markov Decision Processes
Shun Zhang (University of Michigan); Edmund Durfee (University of Michigan); Satinder Singh (University of Michigan)
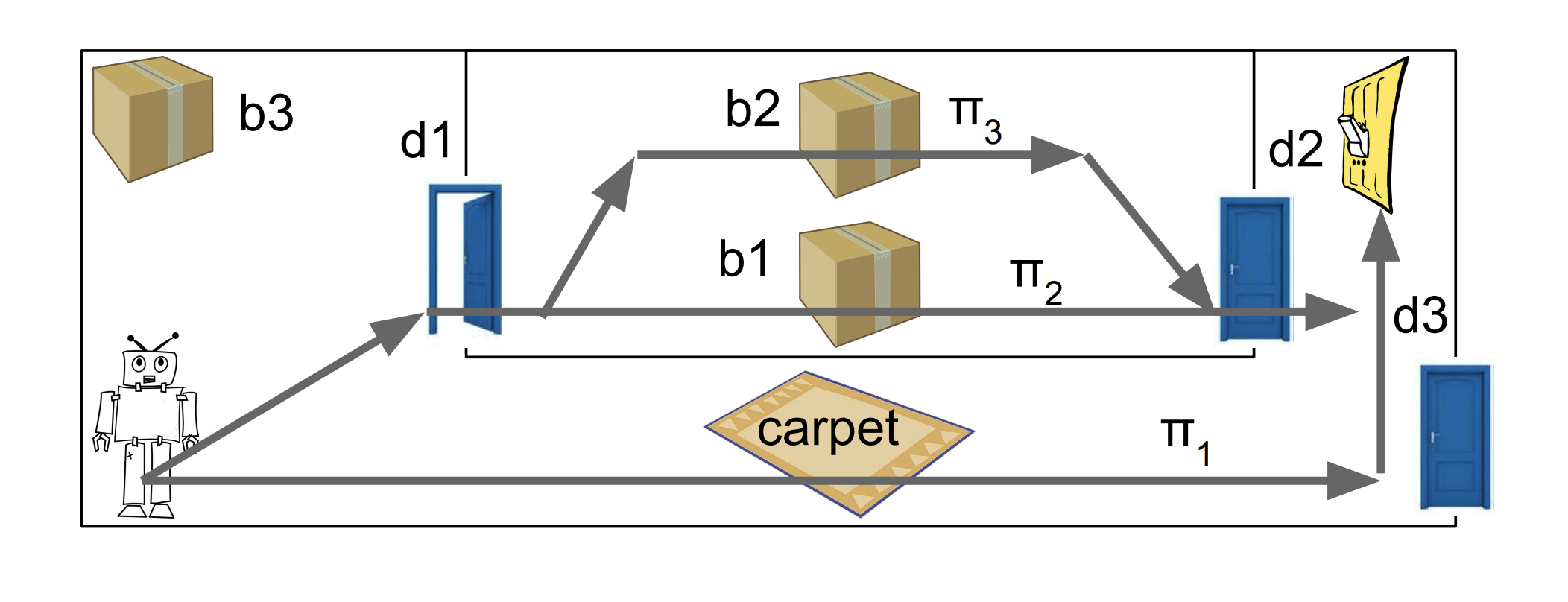
An autonomous agent acting on behalf of a human user has the potential of causing side-effects that surprise the user in unsafe ways. When the agent cannot formulate a policy with only side-effects it knows are safe, it needs to selectively query the user about whether other useful side-effects are safe. The goal of this paper was to design an algorithm that queries about as few potential side-effects as possible to find a safe policy, or to prove that none exists.
 Enlarge
EnlargeStructure Learning for Approximate Solution of Many-Player Games
Zun Li (University of Michigan); Michael Wellman (University of Michigan)
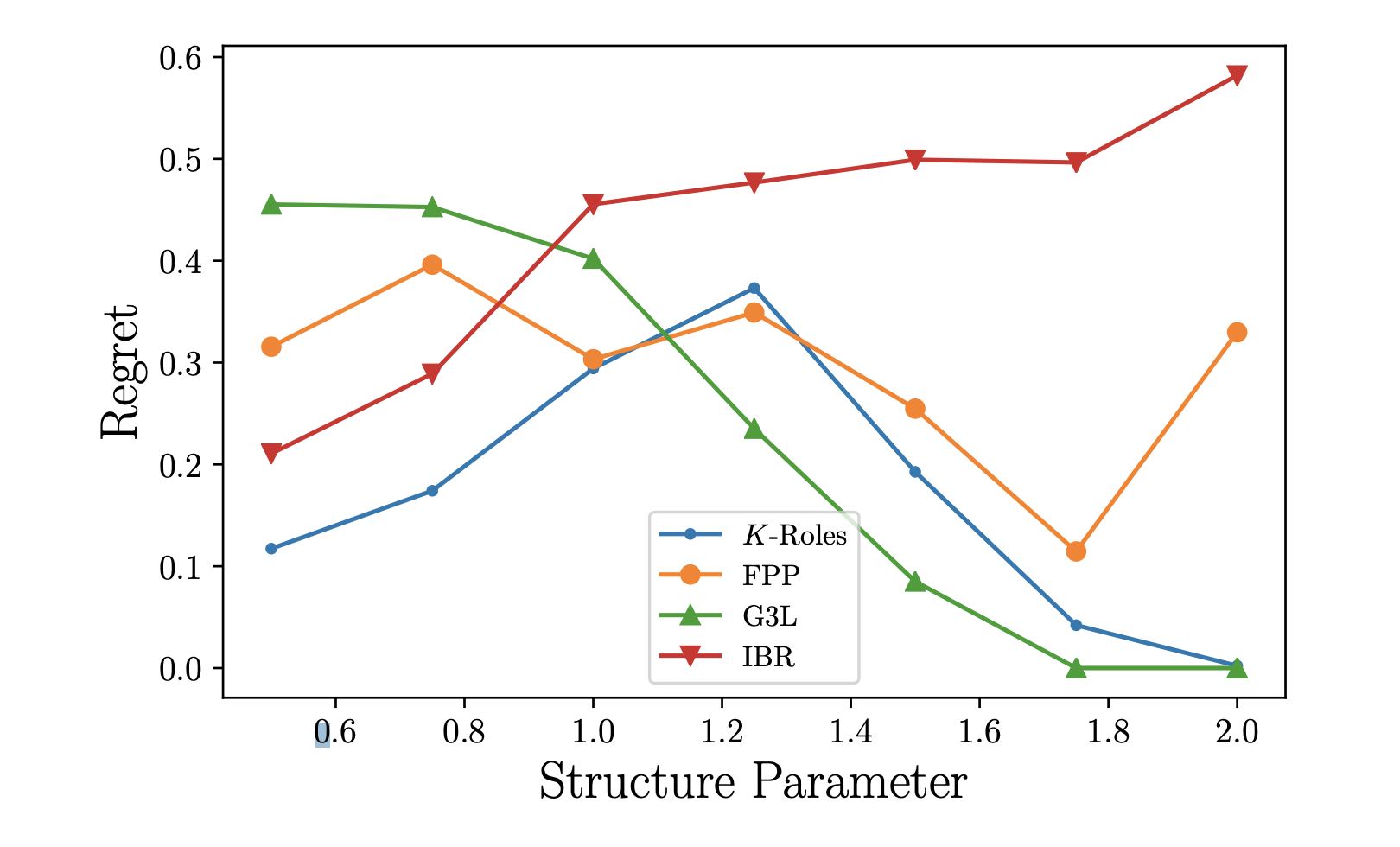
Many of the real-world multiagent systems we would like to understand strategically involve an enormous number of interacting (or potentially interacting) agents. Because of this, games with many players are difficult to solve or even specify without adopting structural assumptions that enable their representation in compact form. The authors designed an iterative structure-learning approach to search for approximate solutions of many-player games. The first algorithm exploits symmetry by learning a role assignment for players of the game through unsupervised learning methods, and the second seeks sparsity by greedy search over local interactions to learn a graphical game model.
 Enlarge
EnlargeUnified Vision-Language Pre-Training for Image Captioning and VQA
Luowei Zhou (University of Michigan); Hamid Palangi (Microsoft Research); Lei Zhang (Microsoft); Houdong Hu (Microsoft AI and Research); Jason Corso (University of Michigan); Jianfeng Gao (Microsoft Research)
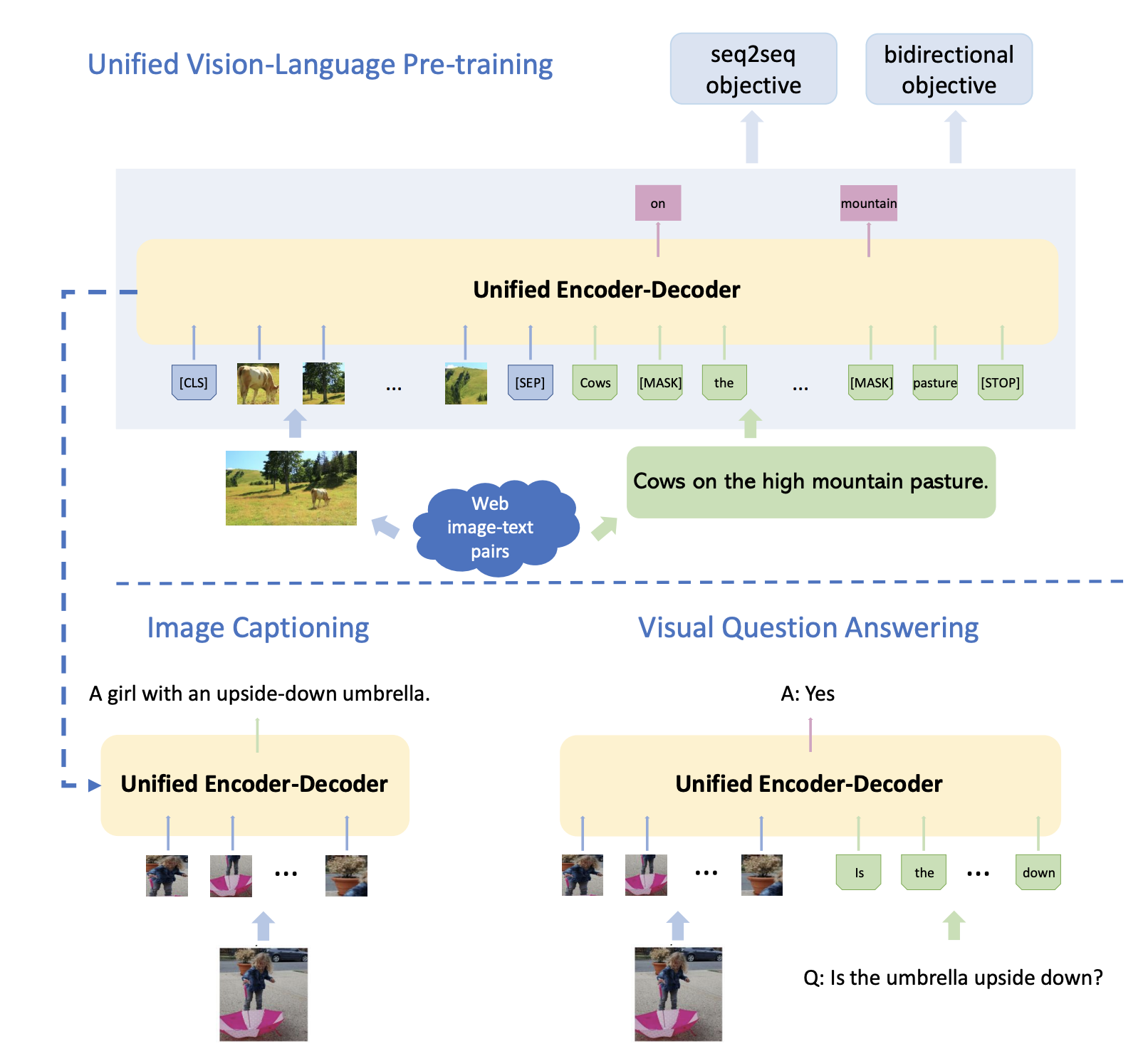
In this paper, the authors apply pre-training models (which have found success in language-based tasks) to visual problems, like image and video captioning or visual question answering. Called Vision-Language Pre-training (VLP), their model is the first reported model that achieves state-of-the-art results on both vision-language generation and understanding tasks, across three challenging benchmark data sets.